![[SP TECH COLUMN] AI 휴먼을 사람처럼 말하게 하는 5가지 방법](/KR/fnc/download.php?file=64a515de2be85.png)
![[SP TECH COLUMN] AI 휴먼을 사람처럼 말하게 하는 5가지 방법](/KR/fnc/download.php?file=64ae82483ae13.jpg)
KEYWORDS
#인공지능 #사람얼굴 #토킹페이스제너레이션

LG전자의 AI 휴먼 김래아 ⓒ LG전자
안녕하세요, AI 읽어주는 남자 신윤호입니다. AI를 이용해 만들어진 아바타 혹은 페르소나, 다들 많이 접해보셨죠? AI 휴먼이라고도 불리는 이들은 마치 사람 같이 혹은 사람보다 더 생생하게 움직이고 이야기합니다. 오늘은 AI 휴먼, 특히 말하는 페르소나를 생성하는데 중요한 기술 중 하나인 토킹 페이스 제너레이션(Talking Face Generation)에 대해 이야기해 보려고 합니다.
토킹 페이스 제너레이션(Talking Face Generation)이란?
말 그대로 말하는 사람의 얼굴을 만들어 내는 AI 기술입니다. 사람은 말할 때 특유의 습관이 있습니다. 목소리(음성신호), 얼굴 움직임(영상신호) 등, 이러한 각각의 신호는 AI가 마치 사람처럼 말하고 행동하기 위한 중요한 데이터가 되죠.
이렇게 영상, 음성, 텍스트 등 여러 가지 형태의 데이터를 멀티모달 데이터(multimodal data)라고 하는데요. 이런 데이터를 활용하려면, 그 전에 먼저 이런 멀티모달 데이터를 인식하는 기술이 필요합니다. 때문에 컴퓨터비전(컴퓨터로 인간의 시각 인식을 재현하는 연구 분야)이나 음성 혹은 자연어 분야 등에 대한 높은 이해가 필요하죠.
국내에서 여러 회사들이 관련 사업을 서비스하고 있는데 특히 딥브레인, 마인즈랩 두 곳이 AI 휴먼의 상용화 서비스를 시작했고 콘텐츠의 품질 또한 상당히 훌륭합니다.

국내업체 딥브레인이 만든 AI 손흥민 ⓒ 딥브레인
사람처럼 말하는 AI를 만드는 5가지 방법
겉으로 보기엔 마술 같지만, 그 안에는 다양한 기술들이 녹아 있습니다. 이번 칼럼에선 토킹 페이스 제너레이션 구현되는 방식을 크게 5가지 정도로 나눠 살펴보겠습니다.
1. 이미지에 마스킹을 이용하는 방법

이 방식은 일반적으로 입이 포함된 얼굴의 하관을 마스킹한(따로 때어낸) 후, 마스킹되지 않은 부분의 이미지 정보와 오디오 데이터가 결합해 딥러닝 네트워크에 입력되어 학습을 통해 (마스킹된)입 모양 부분을 생성하는(inpainting) 기법입니다.
해당 마스킹 영역에 대해서는 안정적인 결과를 보여주지만, 2D 기반에 정해진 템플릿에서만 학습을 하기 때문에 생성 얼굴의 구도를 바꿀 순 없습니다. 즉 3D 화면으로 요리조리 돌려볼 순 없어 자유도가 떨어진다는 뜻이죠. 대표기법으로는 Wav2lip, ATVGNet 등이 있습니다.
2. 얼굴의 랜드마크를 이용한 방법

얼굴의 특징점들을 보통 딥러닝 검출기(Face Detector)를 이용하여 2D 혹은 3D 위치 좌표 형태로 검출해 데이터 전처리로 사용하는 경우가 많은데요, 이 특징점들을 얼굴의 랜드마크(Landmark)라고 부릅니다. 검출 기술에 따라서 2D 랜드마크를 뽑는 경우(Dlib face detector, Mediapipe 등)와 3D 랜드마크(3DMM 등)를 뽑는 경우로 나뉩니다.
특히 요즘의 최신 연구들에선 3D 랜드마크 정보를 이용해서 보다 정교한 얼굴 생성하려는 추세가 보입니다. AD-NeRF, Lipsync-3D, Imitating Arbitrary Talking Style for Realistic Audio-Driven Talking Face Synthesis 등이 랜드마크를 이용한 방식들의 사례입니다.
3. 텍스트 데이터를 이용하는 방법

오디오 대신 텍스트 데이터를 입력해 이에 따른 얼굴을 생성하는 기법으로, 텍스트 데이터를 TTS 음성 합성(TTS, Text-to-Speech) 또는 피쳐 스페이스(feature space, 딥러닝 모델의 학습에 이용할 수 있는 정보의 공간)로 전달해 얼굴 생성 학습에 활용하기도 합니다.
특히 뉴스를 읽거나 동화책을 읽어주는 등 텍스트 스크립트 입력을 통해 영상을 만드는 작업에서 매우 유용한 방식이라 할 수 있는데요. 이 방식의 대표적인 사례는 Text2Video, Obamanet, AnyoneNet 등이 있습니다.
4. 감정 정보를 이용하는 방법

이 방식은 굉장히 흥미롭습니다. 감정이라는 정보는 주관성이 강하다 보니 아직 딥러닝에서 사용하기에는 쉽지 않은 것이 사실입니다. 하지만 사람은 감정에 따라 얼굴 표정이 달라지죠. 여기에 착안해 특정 감정을 부여해 AI 휴먼의 얼굴 표정을 다르게 생성하는 기술도 연구되고 있습니다.
예를 들면 아이들 동화책 읽는 프로그램을 보면 이야기해 주시는 분들의 감정 표현이 굉장히 풍부한 것을 알 수 있죠. “공룡이 나타났어요!”라고 하면서 놀라는 표정을 짓는 것처럼 말이죠. 단순히 음성이나 움직임을 구현하는 것과 달리 ‘감정’이라는 요소를 고려한 방식이기 때문에, 상호간 자연스러운 소통이 필요한 콘텐츠에서 유용하게 쓰여질 기술이라 할 수 있습니다.
대표기법으로는 Speech driven talking face generation from a single image and an emotion condition 등이 있습니다.
5. 하나의 이미지 입력 기반 방법
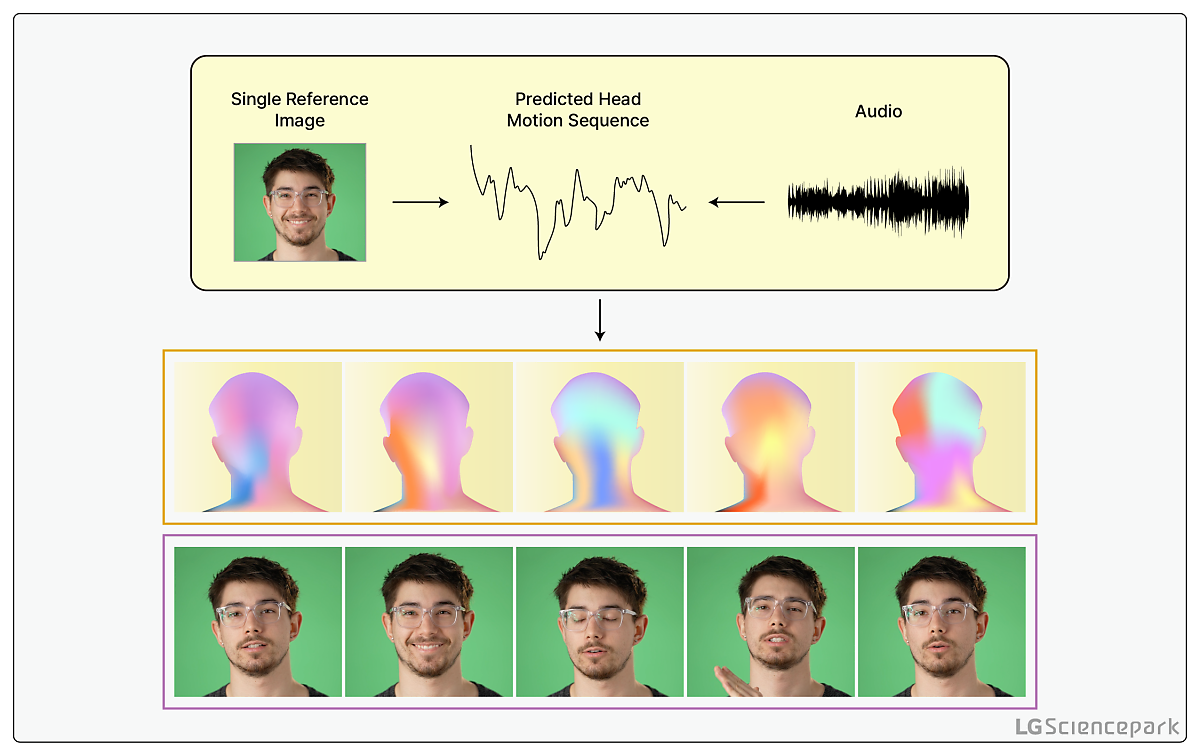
위에서 설명 드린 기법들은 대부분 학습에 동영상 데이터가 필요한 경우가 많은데요. 이번에 설명드릴릴 것은 (여러 장의 연속 이미지가 포함된)동영상 데이터 대신 이미지 한 장만으로 오디오와 함께 AI의 학습에 사용하는 기법입니다.
이런 기법을 이미지 원샷러닝(one shot learning)이라고 부르는데요. 한 장의 사진만으로 이렇게 말하는 장면을 구현할 수 있는 이유는, 원샷러닝에서는 AI가 다양한 인물들로 구성된 대규모 데이터를 학습해둔 덕분입니다. 그렇기에 어떤 이미지 데이터가 들어와도 잘 적용될 수 있게 일반 모델(General Model)을 만드는 것이 이 기법에서 가장 핵심적이라고 볼 수 있습니다.
데이터가 제한적인 분야이기 때문에 실제 모델 사용시 이미지 한 장만 있어도 된다는 것은 큰 장점인데요.
반면에 여러 데이터를 사용하는 기법들에 비해 생성 퀄리티가 좋지 않다는 것은 단점으로 볼 수 있습니다. 하지만 여러분 만약 내 사진만 넣으면 내가 말하는 영상이 나오는 앱이 있다면 사용해 보지 않을까요?
이렇듯 실제 사용자 편의성을 고려할 때는 사진 데이터 1장만이 필요한 이 방법론은 여전히 가능성이 크다고 볼 수 있겠습니다. 대표기법으로 Audio2Head, 3D Talking Face with personalized pose dynamics 등이 있습니다.
AI 기술은 마치 마법처럼 느껴지는데요, 그 안에는 마법을 만들어 내기 위한 다양한 주문들이 있답니다. 오늘은 사람처럼 자연스럽게 말하는 AI를 만드는 주문, 토킹 페이스 제너레이션에 대해 이야기해보았습니다. 다음에는 더욱 흥미롭고 새로운 주문을 가지고 찾아오겠습니다.
